随着视频内容的普及和多样化,越来越多的人对于视听体验的要求也越来越高。然而,仍然存在许多观众由于听力障碍或者其他原因无法享受到视频内容带来的乐趣。为了解决这一问题,使用PR自动识别声音并添加字幕的技术成为了一个重要的研究方向。本文将详细介绍这一技术的原理、应用以及未来的发展方向。

PR自动识别技术概述
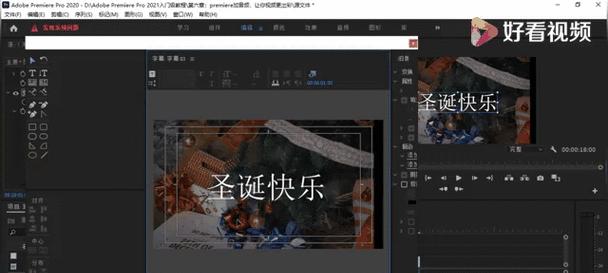
PR(PremierePro)是一款常用的视频编辑软件,其自动识别声音功能可以将视频中的语音转换为文本。这项技术基于强大的语音识别算法,通过分析声音的频谱、音调和音频特征等信息,将声音转化为文字,并将其与视频进行同步。
声音识别与字幕添加的原理
1.声音识别原理

PR利用先进的声音识别算法,对输入的声音进行频谱分析、语音识别和文本转换等处理。通过机器学习和深度神经网络的训练,PR能够准确地将声音中的文字信息提取出来。
2.字幕添加原理
PR根据识别出的文字信息,将其添加到视频的对应位置上。用户可以自定义字幕的样式、位置和显示时间等属性,以满足不同的需求。

PR自动识别声音添加字幕的应用场景
1.视频无障碍传播
通过自动识别声音并添加字幕,PR可以帮助听力障碍者更好地理解视频内容,实现无障碍传播。
2.提高语言学习效果
对于外语学习者来说,字幕的添加可以帮助他们更好地理解和学习语言,并提高学习效果。
3.视频内容检索
PR自动识别声音功能还可以将视频中的声音转化为文本后进行索引,方便用户通过关键词快速搜索到感兴趣的视频片段。
PR自动识别技术的优势与挑战
1.优势
PR自动识别技术具有高准确性、实时性和可定制性等优势,能够快速处理大量的视频内容,并适应不同用户的需求。
2.挑战
然而,PR自动识别技术仍然面临一些挑战,比如对于特定音频环境的适应性不足、多语种识别准确性等问题需要进一步研究和改进。
PR自动识别技术的发展趋势
1.深度学习的应用
随着深度学习技术的不断发展,将其应用到PR自动识别技术中,有望提高声音识别和字幕添加的准确性。
2.多模态融合
PR自动识别技术有望与图像识别、情感分析等其他技术进行融合,实现更加全面和智能的声音处理和字幕添加。
通过PR自动识别声音并添加字幕的技术,视频内容可以实现无障碍传播,提高了观众的体验。随着技术的不断进步和应用场景的扩展,PR自动识别技术将会有更加广阔的发展前景,并为视频内容的创作者和观众带来更多便利与乐趣。